. DOI: 10.1016/S2589-7500(22)00063-2″ width=”800″ height=”381″/><figcaption class=")
آموزش نادرست الگوریتم ها یک مشکل حیاتی است. زمانی که هوش مصنوعی افکار ناخودآگاه، نژادپرستی و تعصبات افرادی را که این الگوریتمها را تولید کردهاند منعکس میکند، میتواند به آسیبهای جدی منجر شود. برای مثال، برنامههای رایانهای به اشتباه متهمان سیاهپوست را دو برابر بیشتر از افرادی که سفیدپوست هستند برای تجاوز مجدد نشان میدهند. زمانی که یک هوش مصنوعی از هزینه به عنوان جایگزینی برای نیازهای بهداشتی استفاده می کرد، به اشتباه بیماران سیاه پوست را سالم تر از سفیدپوستان به همان اندازه بیمار معرفی می کرد، زیرا پول کمتری برای آنها خرج می شد. حتی هوش مصنوعی برای نوشتن نمایشنامهای متکی بر استفاده از کلیشههای مضر برای انتخاب بازیگران بود.
به نظر می رسد حذف ویژگی های حساس از داده ها یک ترفند قابل اجرا است. اما وقتی کافی نیست چه اتفاقی می افتد؟
نمونه هایی از سوگیری در پردازش زبان طبیعی بی حد و حصر هستند – اما دانشمندان MIT روش مهم دیگری را بررسی کرده اند که تا حد زیادی مورد بررسی قرار نگرفته است: تصاویر پزشکی. این تیم با استفاده از مجموعه دادههای خصوصی و عمومی دریافت که هوش مصنوعی میتواند بهطور دقیق نژاد گزارششده بیماران را تنها از روی تصاویر پزشکی پیشبینی کند. این تیم با استفاده از داده های تصویربرداری اشعه ایکس قفسه سینه، اشعه ایکس اندام ها، سی تی اسکن قفسه سینه و ماموگرافی، یک مدل یادگیری عمیق را آموزش دادند تا نژاد را سفید، سیاه یا آسیایی تشخیص دهد – حتی اگر خود تصاویر هیچ اشاره ای به این نژاد نداشتند. نژاد بیمار این شاهکاری است که حتی با تجربه ترین پزشکان هم نمی توانند انجام دهند، و مشخص نیست که چگونه مدل توانسته این کار را انجام دهد.
محققان در تلاشی برای کنایه زدن و درک معمایی “چگونه” این همه، آزمایش های زیادی را انجام دادند. برای بررسی مکانیسمهای احتمالی تشخیص نژاد، آنها به متغیرهایی مانند تفاوت در آناتومی، تراکم استخوان، وضوح تصاویر و بسیاری موارد دیگر نگاه کردند و مدلها همچنان با توانایی بالایی در تشخیص نژاد از طریق اشعه ایکس قفسه سینه غالب بودند. مرضیه قاسمی، یکی از نویسندگان مقاله، استادیار دپارتمان مهندسی برق و علوم کامپیوتر MIT می گوید: «این نتایج در ابتدا گیج کننده بود، زیرا اعضای تیم تحقیقاتی ما نتوانستند به شناسایی یک پروکسی خوب برای این کار نزدیک شوند. و موسسه مهندسی و علوم پزشکی (IMES)، که وابسته به آزمایشگاه علوم کامپیوتر و هوش مصنوعی (CSAIL) و کلینیک MIT Jameel است. حتی زمانی که تصاویر پزشکی را فیلتر میکنید که در آن تصاویر بهعنوان تصاویر پزشکی قابل تشخیص هستند، مدلهای عمیق عملکرد بسیار بالایی دارند.
در یک محیط بالینی، الگوریتمها میتوانند به ما کمک کنند که بگوییم آیا بیمار کاندیدای شیمیدرمانی است یا خیر، تریاژ بیماران را دیکته میکند یا تصمیم میگیرد که آیا انتقال به ICU ضروری است یا خیر. ما فکر میکنیم که الگوریتمها فقط علائم حیاتی یا آزمایشهای آزمایشگاهی را بررسی میکنند، اما این امکان وجود دارد که به نژاد، قومیت، جنسیت شما، زندانی بودن یا نبودن شما نیز توجه کنند، حتی اگر همه این اطلاعات پنهان باشد. لئو آنتونی سلی، یکی از نویسندگان مقاله، دانشمند پژوهشی اصلی در IMES در MIT و دانشیار پزشکی در دانشکده پزشکی هاروارد می گوید. “فقط به این دلیل که شما در الگوریتمهای خود نمایشی از گروههای مختلف دارید، این تضمین نمیکند که نابرابریها و نابرابریهای موجود را تداوم یا بزرگتر نکند. تغذیه الگوریتمها با دادههای بیشتر با بازنمایی، نوشدارویی نیست. این مقاله باید ما را مکث کند. واقعاً تجدید نظر کنید که آیا ما آماده ایم هوش مصنوعی را کنار تخت بیاوریم.»
این مطالعه با عنوان “تشخیص هوش مصنوعی نژاد بیمار در تصویربرداری پزشکی: یک مطالعه مدل سازی” در منتشر شد سلامت دیجیتال Lancet در 11 می. سلی و قاسمی این مقاله را در کنار 20 نویسنده دیگر در چهار کشور نوشتند.
برای تنظیم این آزمایشها، دانشمندان ابتدا نشان دادند که این مدلها قادر به پیشبینی نژاد در چندین روش تصویربرداری، مجموعه دادههای مختلف، و وظایف بالینی متنوع، و همچنین در میان طیف وسیعی از مراکز دانشگاهی و جمعیت بیماران در ایالات متحده هستند. آنها از سه مجموعه داده پرتو ایکس قفسه سینه استفاده کردند و مدل را روی یک زیرمجموعه نامرئی از مجموعه داده مورد استفاده برای آموزش مدل آزمایش کردند و مدلی کاملاً متفاوت. در مرحله بعد، آنها مدل های تشخیص هویت نژادی را برای تصاویر غیر اشعه ایکس قفسه سینه از مکان های مختلف بدن، از جمله رادیوگرافی دیجیتال، ماموگرافی، رادیوگرافی جانبی ستون فقرات گردنی، و سی تی قفسه سینه آموزش دادند تا ببینند آیا عملکرد مدل به اشعه ایکس قفسه سینه محدود است یا خیر.
این تیم در تلاش برای توضیح رفتار مدل، مبانی بسیاری را پوشش داد: تفاوت در ویژگیهای فیزیکی بین گروههای نژادی مختلف (عادت بدن، تراکم سینه)، توزیع بیماری (مطالعات قبلی نشان داده است که بیماران سیاهپوست بیشتر در معرض مشکلات سلامتی مانند بیماری قلبی هستند. )، تفاوتهای خاص مکان یا بافت، اثرات سوگیری اجتماعی و استرس محیطی، توانایی سیستمهای یادگیری عمیق برای تشخیص نژاد زمانی که عوامل جمعیتی و بیمار متعدد ترکیب میشوند، و اینکه آیا مناطق تصویری خاص در تشخیص نژاد نقش داشتهاند.
آنچه ظاهر شد واقعاً حیرتانگیز بود: توانایی مدلها برای پیشبینی نژاد به تنهایی از روی برچسبهای تشخیصی بسیار کمتر از مدلهای مبتنی بر تصویر اشعه ایکس قفسه سینه بود.
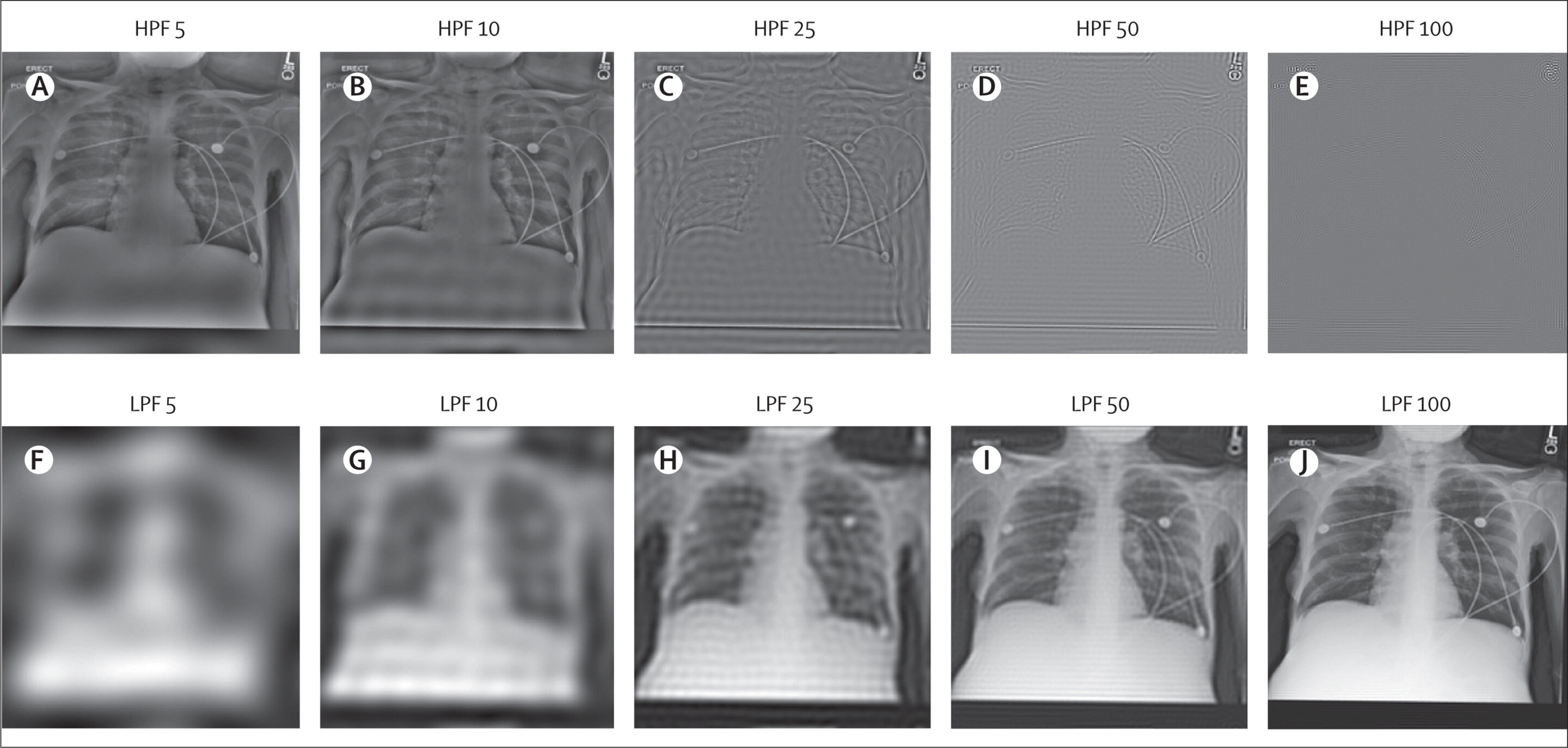
برای مثال، آزمایش تراکم استخوان از تصاویری استفاده کرد که در آن قسمت ضخیمتر استخوان سفید و قسمت نازکتر خاکستریتر یا شفافتر به نظر میرسید. دانشمندان فرض کردند که از آنجایی که افراد سیاه پوست عموماً تراکم استخوانی بالاتری دارند، تفاوت رنگ ها به مدل های هوش مصنوعی کمک کرد تا نژاد را تشخیص دهند. برای قطع آن، آنها تصاویر را با یک فیلتر برش دادند، بنابراین مدل نمی تواند تفاوت رنگ ها را تشخیص دهد. مشخص شد که قطع کردن عرضه رنگ مدل را نگران نمیکند – هنوز هم میتواند بهطور دقیق مسابقات را پیشبینی کند. (مقدار “مساحت زیر منحنی”، به معنی اندازه گیری دقت یک تست تشخیصی کمی، 0.94-0.96 بود). به این ترتیب، به نظر میرسد که ویژگیهای آموختهشده مدل به تمام مناطق تصویر متکی است، به این معنی که کنترل این نوع رفتار الگوریتمی یک مشکل درهم و برهم و چالشبرانگیز را ارائه میکند.
دانشمندان در دسترس بودن محدود برچسبهای هویت نژادی را تصدیق میکنند که باعث شد آنها بر روی جمعیتهای آسیایی، سیاهپوست و سفیدپوست تمرکز کنند و اینکه حقیقت اصلی آنها جزییاتی بود که خود گزارش شده بود. دیگر کارهای آتی شامل بررسی بالقوه جداسازی سیگنالهای مختلف قبل از بازسازی تصویر است، زیرا، مانند آزمایشهای تراکم استخوان، آنها نتوانستند بافت استخوانی باقیمانده را که روی تصاویر وجود دارد، محاسبه کنند.
شایان ذکر است، کار دیگری توسط قاسمی و سلی به رهبری حماد آدام، دانشجوی MIT نشان میدهد که مدلها همچنین میتوانند نژاد گزارششده خود بیمار را از روی یادداشتهای بالینی شناسایی کنند، حتی زمانی که آن یادداشتها فاقد شاخصهای صریح نژاد باشند. درست مانند این کار، متخصصان انسانی قادر به پیشبینی دقیق نژاد بیمار از روی همان یادداشتهای بالینی ویرایششده نیستند.
ما باید دانشمندان علوم اجتماعی را وارد صحنه کنیم. کارشناسان حوزه که معمولاً پزشکان، پزشکان بهداشت عمومی، دانشمندان کامپیوتر و مهندسان هستند کافی نیستند. مراقبت های بهداشتی به همان اندازه که یک مشکل پزشکی است یک مشکل اجتماعی-فرهنگی است. سلی میگوید: ما به گروه دیگری از متخصصان نیاز داریم تا در مورد نحوه طراحی، توسعه، استقرار و ارزیابی این الگوریتمها اطلاعات و بازخورد ارائه دهند. “ما همچنین باید از دانشمندان داده بپرسیم، قبل از هر گونه کاوش در داده ها، آیا تفاوت هایی وجود دارد؟ کدام گروه های بیمار به حاشیه رانده شده اند؟ محرک های این نابرابری ها چیست؟ آیا دسترسی به مراقبت است؟ آیا از ذهنیت ارائه دهندگان مراقبت است؟ اگر آن را درک نکنیم، شانسی برای شناسایی پیامدهای ناخواسته الگوریتمها نخواهیم داشت، و هیچ راهی وجود ندارد که بتوانیم از الگوریتمها در برابر تعصبات دائمی محافظت کنیم.»
زیاد اوبرمایر، دانشیار دانشگاه میگوید: «این واقعیت که الگوریتمها «نژاد را میبینند»، همانطور که نویسندگان به طور قانعکنندهای مستند میکنند، میتواند خطرناک باشد. اما یک واقعیت مهم و مرتبط این است که در صورت استفاده دقیق، الگوریتمها میتوانند برای مقابله با سوگیری نیز کار کنند. دانشگاه کالیفرنیا در برکلی، که تحقیقات آن بر روی هوش مصنوعی کاربردی در سلامت متمرکز است. “در کار خودمان، به رهبری دانشمند کامپیوتر، اما پیرسون در کورنل، نشان دادیم که الگوریتم هایی که از تجربیات درد بیماران می آموزند، می توانند منابع جدیدی از درد زانو را در اشعه ایکس پیدا کنند که به طور نامتناسبی بر بیماران سیاه پوست تاثیر می گذارد – و به طور نامتناسبی توسط رادیولوژیست ها نادیده گرفته می شود. بنابراین درست مانند هر ابزار دیگری، الگوریتمها میتوانند نیرویی برای شر یا نیرویی برای خیر باشند – که این به ما و انتخابهایی که هنگام ساختن الگوریتمها انجام میدهیم بستگی دارد.»
سوگیری های پنهان در داده های پزشکی می تواند رویکردهای هوش مصنوعی در مراقبت های بهداشتی را به خطر بیندازد
جودی واویرا گیچویا و همکاران، تشخیص هوش مصنوعی نژاد بیمار در تصویربرداری پزشکی: یک مطالعه مدل سازی، سلامت دیجیتال Lancet (2022). DOI: 10.1016/S2589-7500(22)00063-2
ارائه شده توسط موسسه فناوری ماساچوست
این داستان با حسن نیت از MIT News (web.mit.edu/newsoffice/)، یک سایت محبوب که اخبار مربوط به تحقیقات، نوآوری و آموزش MIT را پوشش می دهد، بازنشر شده است.
نقل قول: هوش مصنوعی نژاد بیماران را از روی تصاویر پزشکی آنها پیش بینی می کند (2022، 20 مه) در 20 مه 2022 از https://medicalxpress.com/news/2022-05-artificial-intelligence-patients-medical-images.html بازیابی شده است.
این برگه یا سند یا نوشته تحت پوشش قانون کپی رایت است. به غیر از هرگونه معامله منصفانه به منظور مطالعه یا تحقیق خصوصی، هیچ بخشی بدون اجازه کتبی قابل تکثیر نیست. محتوای مذکور فقط به هدف اطلاع رسانی ایجاد شده است.